 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAP-Textured Gaussians: Enhancing Textured Gaussians with Adaptive Sampling and Anisotropic Parameterization
Dec 16, 2025



Recent advances have equipped 3D Gaussian Splatting with texture parameterizations to capture spatially varying attributes, improving the performance of both appearance modeling and downstream tasks. However, the added texture parameters introduce significant memory efficiency challenges. Rather than proposing new texture formulations, we take a step back to examine the characteristics of existing textured Gaussian methods and identify two key limitations in common: (1) Textures are typically defined in canonical space, leading to inefficient sampling that wastes textures' capacity on low-contribution regions; and (2) texture parameterization is uniformly assigned across all Gaussians, regardless of their visual complexity, resulting in over-parameterization. In this work, we address these issues through two simple yet effective strategies: adaptive sampling based on the Gaussian density distribution and error-driven anisotropic parameterization that allocates texture resources according to rendering error. Our proposed ASAP Textured Gaussians, short for Adaptive Sampling and Anisotropic Parameterization, significantly improve the quality efficiency tradeoff, achieving high-fidelity rendering with far fewer texture parameters.
FUSER: Feed-Forward MUltiview 3D Registration Transformer and SE(3)$^N$ Diffusion Refinement
Dec 10, 2025Registration of multiview point clouds conventionally relies on extensive pairwise matching to build a pose graph for global synchronization, which is computationally expensive and inherently ill-posed without holistic geometric constraints. This paper proposes FUSER, the first feed-forward multiview registration transformer that jointly processes all scans in a unified, compact latent space to directly predict global poses without any pairwise estimation. To maintain tractability, FUSER encodes each scan into low-resolution superpoint features via a sparse 3D CNN that preserves absolute translation cues, and performs efficient intra- and inter-scan reasoning through a Geometric Alternating Attention module. Particularly, we transfer 2D attention priors from off-the-shelf foundation models to enhance 3D feature interaction and geometric consistency. Building upon FUSER, we further introduce FUSER-DF, an SE(3)$^N$ diffusion refinement framework to correct FUSER's estimates via denoising in the joint SE(3)$^N$ space. FUSER acts as a surrogate multiview registration model to construct the denoiser, and a prior-conditioned SE(3)$^N$ variational lower bound is derived for denoising supervision. Extensive experiments on 3DMatch, ScanNet and ArkitScenes demonstrate that our approach achieves the superior registration accuracy and outstanding computational efficiency.
Generative Point Cloud Registration
Dec 10, 2025In this paper, we propose a novel 3D registration paradigm, Generative Point Cloud Registration, which bridges advanced 2D generative models with 3D matching tasks to enhance registration performance. Our key idea is to generate cross-view consistent image pairs that are well-aligned with the source and target point clouds, enabling geometry-color feature fusion to facilitate robust matching. To ensure high-quality matching, the generated image pair should feature both 2D-3D geometric consistency and cross-view texture consistency. To achieve this, we introduce Match-ControlNet, a matching-specific, controllable 2D generative model. Specifically, it leverages the depth-conditioned generation capability of ControlNet to produce images that are geometrically aligned with depth maps derived from point clouds, ensuring 2D-3D geometric consistency. Additionally, by incorporating a coupled conditional denoising scheme and coupled prompt guidance, Match-ControlNet further promotes cross-view feature interaction, guiding texture consistency generation. Our generative 3D registration paradigm is general and could be seamlessly integrated into various registration methods to enhance their performance. Extensive experiments on 3DMatch and ScanNet datasets verify the effectiveness of our approach.
Normal-GS: 3D Gaussian Splatting with Normal-Involved Rendering
Oct 27, 2024



Rendering and reconstruction are long-standing topics in computer vision and graphics. Achieving both high rendering quality and accurate geometry is a challenge. Recent advancements in 3D Gaussian Splatting (3DGS) have enabled high-fidelity novel view synthesis at real-time speeds. However, the noisy and discrete nature of 3D Gaussian primitives hinders accurate surface estimation. Previous attempts to regularize 3D Gaussian normals often degrade rendering quality due to the fundamental disconnect between normal vectors and the rendering pipeline in 3DGS-based methods. Therefore, we introduce Normal-GS, a novel approach that integrates normal vectors into the 3DGS rendering pipeline. The core idea is to model the interaction between normals and incident lighting using the physically-based rendering equation. Our approach re-parameterizes surface colors as the product of normals and a designed Integrated Directional Illumination Vector (IDIV). To optimize memory usage and simplify optimization, we employ an anchor-based 3DGS to implicitly encode locally-shared IDIVs. Additionally, Normal-GS leverages optimized normals and Integrated Directional Encoding (IDE) to accurately model specular effects, enhancing both rendering quality and surface normal precision. Extensive experiments demonstrate that Normal-GS achieves near state-of-the-art visual quality while obtaining accurate surface normals and preserving real-time rendering performance.
Differentiable Convex Polyhedra Optimization from Multi-view Images
Jul 22, 2024This paper presents a novel approach for the differentiable rendering of convex polyhedra, addressing the limitations of recent methods that rely on implicit field supervision. Our technique introduces a strategy that combines non-differentiable computation of hyperplane intersection through duality transform with differentiable optimization for vertex positioning with three-plane intersection, enabling gradient-based optimization without the need for 3D implicit fields. This allows for efficient shape representation across a range of applications, from shape parsing to compact mesh reconstruction. This work not only overcomes the challenges of previous approaches but also sets a new standard for representing shapes with convex polyhedra.
ObjectSDF++: Improved Object-Compositional Neural Implicit Surfaces
Aug 17, 2023In recent years, neural implicit surface reconstruction has emerged as a popular paradigm for multi-view 3D reconstruction. Unlike traditional multi-view stereo approaches, the neural implicit surface-based methods leverage neural networks to represent 3D scenes as signed distance functions (SDFs). However, they tend to disregard the reconstruction of individual objects within the scene, which limits their performance and practical applications. To address this issue, previous work ObjectSDF introduced a nice framework of object-composition neural implicit surfaces, which utilizes 2D instance masks to supervise individual object SDFs. In this paper, we propose a new framework called ObjectSDF++ to overcome the limitations of ObjectSDF. First, in contrast to ObjectSDF whose performance is primarily restricted by its converted semantic field, the core component of our model is an occlusion-aware object opacity rendering formulation that directly volume-renders object opacity to be supervised with instance masks. Second, we design a novel regularization term for object distinction, which can effectively mitigate the issue that ObjectSDF may result in unexpected reconstruction in invisible regions due to the lack of constraint to prevent collisions. Our extensive experiments demonstrate that our novel framework not only produces superior object reconstruction results but also significantly improves the quality of scene reconstruction. Code and more resources can be found in \url{https://qianyiwu.github.io/objectsdf++}
Multi-objective Anti-swing Trajectory Planning of Double-pendulum Tower Crane Operations using Opposition-based Evolutionary Algorithm
May 30, 2023Underactuated tower crane lifting requires time-energy optimal trajectories for the trolley/slew operations and reduction of the unactuated swings resulting from the trolley/jib motion. In scenarios involving non-negligible hook mass or long rig-cable, the hook-payload unit exhibits double-pendulum behaviour, making the problem highly challenging. This article introduces an offline multi-objective anti-swing trajectory planning module for a Computer-Aided Lift Planning (CALP) system of autonomous double-pendulum tower cranes, addressing all the transient state constraints. A set of auxiliary outputs are selected by methodically analyzing the payload swing dynamics and are used to prove the differential flatness property of the crane operations. The flat outputs are parameterized via suitable B\'{e}zier curves to formulate the multi-objective trajectory optimization problems in the flat output space. A novel multi-objective evolutionary algorithm called Collective Oppositional Generalized Differential Evolution 3 (CO-GDE3) is employed as the optimizer. To obtain faster convergence and better consistency in getting a wide range of good solutions, a new population initialization strategy is integrated into the conventional GDE3. The computationally efficient initialization method incorporates various concepts of computational opposition. Statistical comparisons based on trolley and slew operations verify the superiority of convergence and reliability of CO-GDE3 over the standard GDE3. Trolley and slew operations of a collision-free lifting path computed via the path planner of the CALP system are selected for a simulation study. The simulated trajectories demonstrate that the proposed planner can produce time-energy optimal solutions, keeping all the state variables within their respective limits and restricting the hook and payload swings.
ExtrudeNet: Unsupervised Inverse Sketch-and-Extrude for Shape Parsing
Sep 30, 2022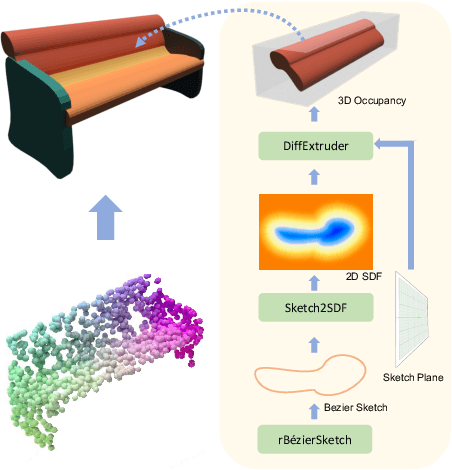
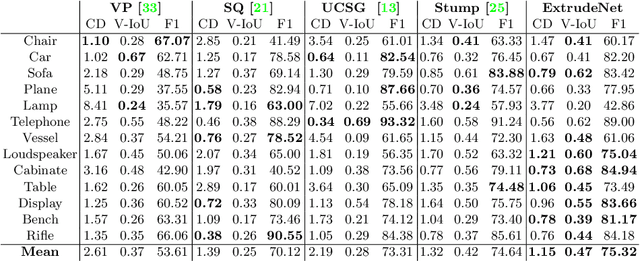
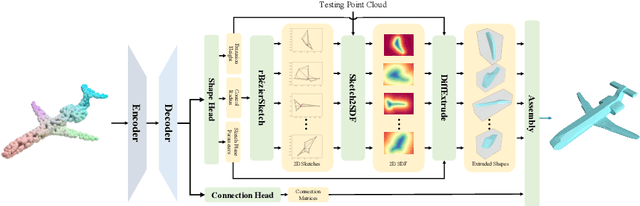

Sketch-and-extrude is a common and intuitive modeling process in computer aided design. This paper studies the problem of learning the shape given in the form of point clouds by inverse sketch-and-extrude. We present ExtrudeNet, an unsupervised end-to-end network for discovering sketch and extrude from point clouds. Behind ExtrudeNet are two new technical components: 1) an effective representation for sketch and extrude, which can model extrusion with freeform sketches and conventional cylinder and box primitives as well; and 2) a numerical method for computing the signed distance field which is used in the network learning. This is the first attempt that uses machine learning to reverse engineer the sketch-and-extrude modeling process of a shape in an unsupervised fashion. ExtrudeNet not only outputs a compact, editable and interpretable representation of the shape that can be seamlessly integrated into modern CAD software, but also aligns with the standard CAD modeling process facilitating various editing applications, which distinguishes our work from existing shape parsing research. Code is released at https://github.com/kimren227/ExtrudeNet.
Object-Compositional Neural Implicit Surfaces
Jul 20, 2022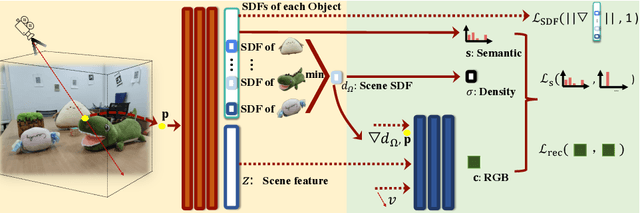
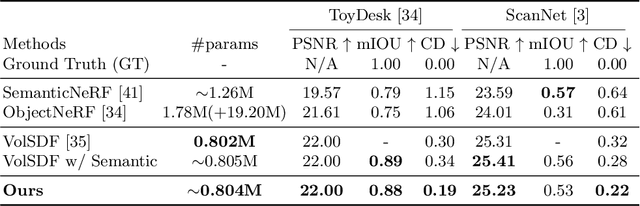
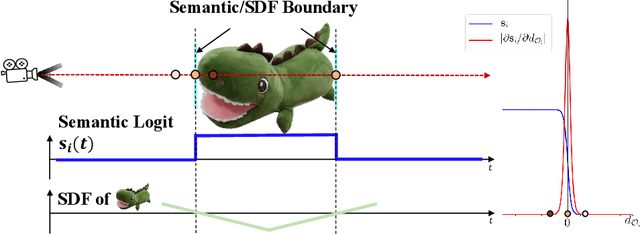
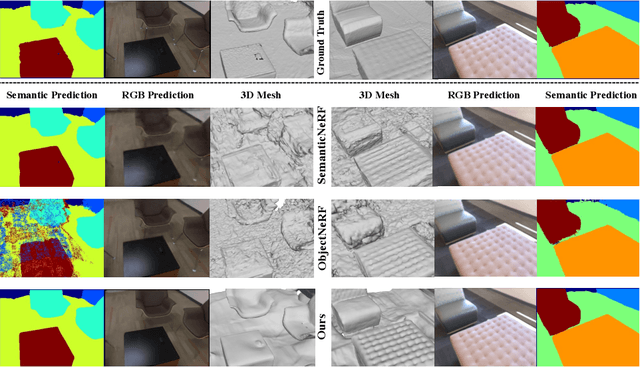
The neural implicit representation has shown its effectiveness in novel view synthesis and high-quality 3D reconstruction from multi-view images. However, most approaches focus on holistic scene representation yet ignore individual objects inside it, thus limiting potential downstream applications. In order to learn object-compositional representation, a few works incorporate the 2D semantic map as a cue in training to grasp the difference between objects. But they neglect the strong connections between object geometry and instance semantic information, which leads to inaccurate modeling of individual instance. This paper proposes a novel framework, ObjectSDF, to build an object-compositional neural implicit representation with high fidelity in 3D reconstruction and object representation. Observing the ambiguity of conventional volume rendering pipelines, we model the scene by combining the Signed Distance Functions (SDF) of individual object to exert explicit surface constraint. The key in distinguishing different instances is to revisit the strong association between an individual object's SDF and semantic label. Particularly, we convert the semantic information to a function of object SDF and develop a unified and compact representation for scene and objects. Experimental results show the superiority of ObjectSDF framework in representing both the holistic object-compositional scene and the individual instances. Code can be found at https://qianyiwu.github.io/objectsdf/
CSG-Stump: A Learning Friendly CSG-Like Representation for Interpretable Shape Parsing
Aug 25, 2021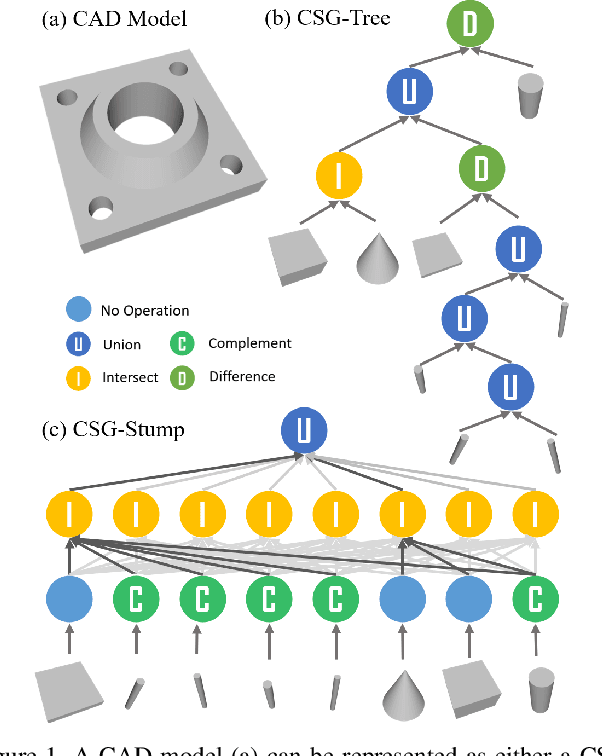

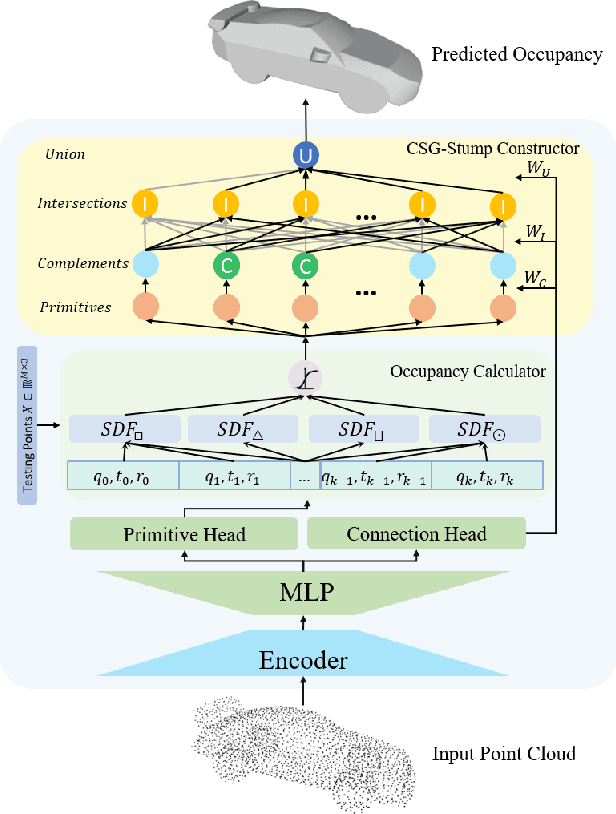
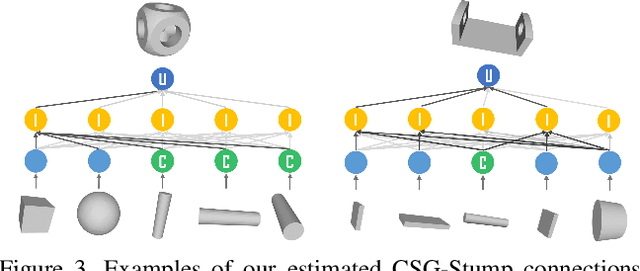
Generating an interpretable and compact representation of 3D shapes from point clouds is an important and challenging problem. This paper presents CSG-Stump Net, an unsupervised end-to-end network for learning shapes from point clouds and discovering the underlying constituent modeling primitives and operations as well. At the core is a three-level structure called {\em CSG-Stump}, consisting of a complement layer at the bottom, an intersection layer in the middle, and a union layer at the top. CSG-Stump is proven to be equivalent to CSG in terms of representation, therefore inheriting the interpretable, compact and editable nature of CSG while freeing from CSG's complex tree structures. Particularly, the CSG-Stump has a simple and regular structure, allowing neural networks to give outputs of a constant dimensionality, which makes itself deep-learning friendly. Due to these characteristics of CSG-Stump, CSG-Stump Net achieves superior results compared to previous CSG-based methods and generates much more appealing shapes, as confirmed by extensive experiments. Project page: https://kimren227.github.io/projects/CSGStump/